Note: A better version of this script is now available here.
So you may have seen in a previous article how I had to remove some duplicate rows in SQL Server that had the same Id. I ran into another issue recently that was a little more complex. Removing duplicate rows based on more than just an Id. Here's how I made it happen.
Here's the situation. In one app I maintain, we have keep a "version" record each time an update is made. We also use a "lock_version" column as a way of preventing concurrency issues when it comes to updating/removing records. Every time a record is updated, the lock version is incremented and a copy of the record is made into our versions table. A quick glance looks something like this:
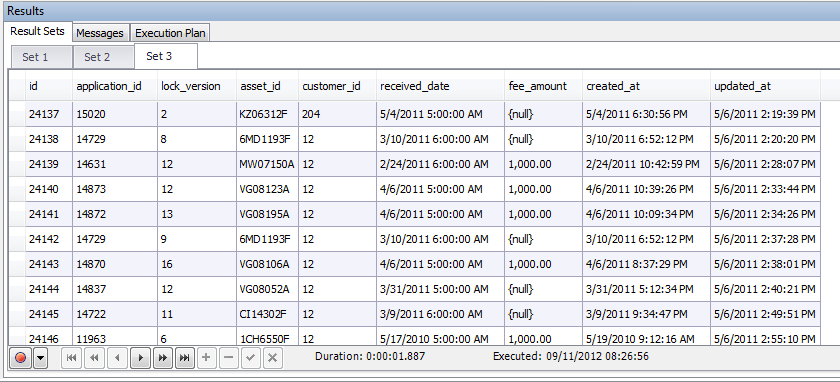
The problem occurred where we were doing multiple updates simultaneously. There are a couple of other tables (an analysis and package table) that were updated in batch with the applications table. This was due to a request of the client. However, the code in place was creating a versions record regardless if the application record was updated itself (since the version or analysis record was updated). As a result, our history (created based off of our versions) was getting corrupted. Running the following query helped us discover these issues:
[gist]3699824
This gives us the following results:
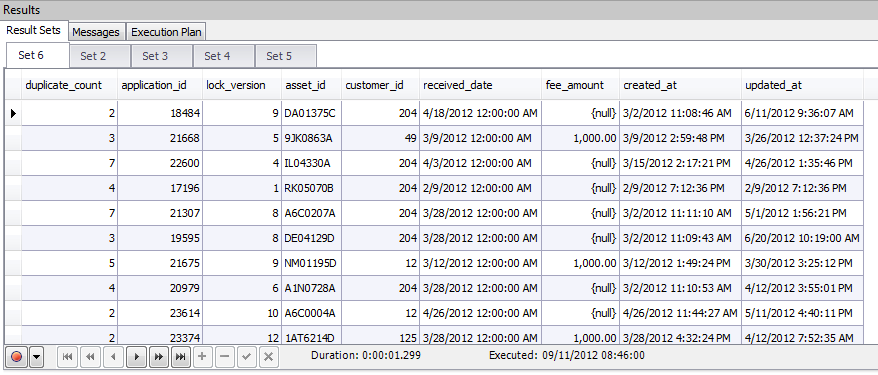
Wow! That's some interesting duplicates in there. You may wonder why I'm grouping based off of all of the fields instead of just the application_id and lock_version. While doing some diagnosis into the table, I discovered a second bug (sheesh I know!) that had duplicate lock_version records, but different data. For example, the lock_version may be the same, but the fee_amount is different. This is a secondary issue I need to resolve, but I don't want to lose the record (which would happen if I group simply off application_id and lock_version. As a result, I group on all the fields so it verifies completely identical records.
How do I go about removing these duplicate records? Obviously doing a simple DELETE WHERE would remove all of my records. One option could possible be to get the unique record Ids (I am fortunate in that regard) and remove all but one of them, but building that kind of list might take a while.
After digging into the SET ROWCOUNT 1 command, I discovered that it will no longer affect DELETE commands (and a few other ones) in SQL Server 2008 and beyond (see the MSDN documentation page) so I figured I should go with a more long term solution. Fortunately, the TOP(x) command DOES work with DELETE statements from here on out, and I suppose it probably is a little more "good from" than the other route. As such, we can now setup an algorithm for our process:
Run query to get all duplicate count values.
Iterate through table.
- Use DELETE TOP(x - 1) remove all duplicates.
Done.
That's all there is to it. However, as all good tricky situations are, there are a couple of glitches to this process.
The first is that we can't use a column name in our (x-1) parameter for using TOP. If so, we could have setup one statement with the JOINS and be done with it. This forces us to go through each row individually. While not particularly complex, this can cause a bit of extra time to run, depending on the columns involved and the rows with duplicate records.
The second (and even more devious) is that some of our rows have NULL values in them. NULL values are notoriously wonky when it comes to creating scripts or function in SQL. JOIN clauses don't always play nice and evaluating WHERE clauses with a variable against a NULL value doesn't work well as well. Fortunately, SQL Server has a ISNULL function (in 2005+) that allows us to assign a value to our NULL values. By setting them to a value we know not to exist in our records, we can handle our NULL values a lot easier. With all that said, here's the final script. Note that we use a table variable to store all our duplicate record data, and I've added a couple "RAISEERROR" statements so that we can track the progress of the script, either in your GUI tool or in a log file that you output to.
[gist]3700029
One final note to this script is that it is not optimized at all. Part of this is due to the nature of the situation we're dealing with. Ideally we'd have all our processing and primary/unique keys in place, but this wasn't the case and a "ugly" approach is needed. In addition, the ISNULL method will also cause a performance hit. So your script may take some time to run, based on the number of duplicate rows to process and the number of columns necessary to join together.
Hopefully this script will get you out of a bind, like it did for me. If you do know any good SQL tuning tricks that could optimize this process, please send them my way. Who knows when I'll have to setup another script like this in the future.